Dfs Queue Or Stack

By Learning This Course You Will Get A Comprehensive Grasp Of Stack Queue Binary Tree Graph And Bst Structures
Breaking Down Breadth First Search By Vaidehi Joshi Basecs Medium
Https Encrypted Tbn0 Gstatic Com Images Q Tbn 3aand9gcsxqc9bhphjyx8txxqfwxq4lbosepncy9s Q Usqp Cau

Write A Program To Calculate Pow X N Geeksforgeeks Writing Calculator Programming

Izobrazhenie Ot Polzovatelya Sekul Kamberov Developer Na Doske Sekul Kamberov Net C C C

Leetcode House Robber Iii Java Java Binary Tree Data Structures

Method of storing nodes.
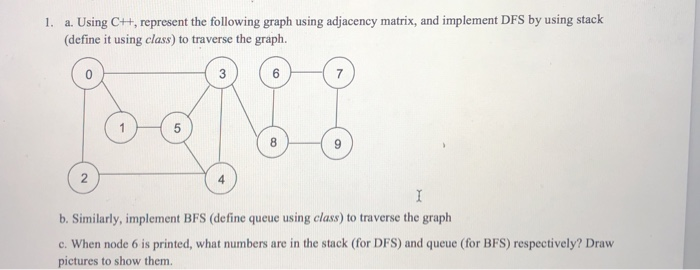
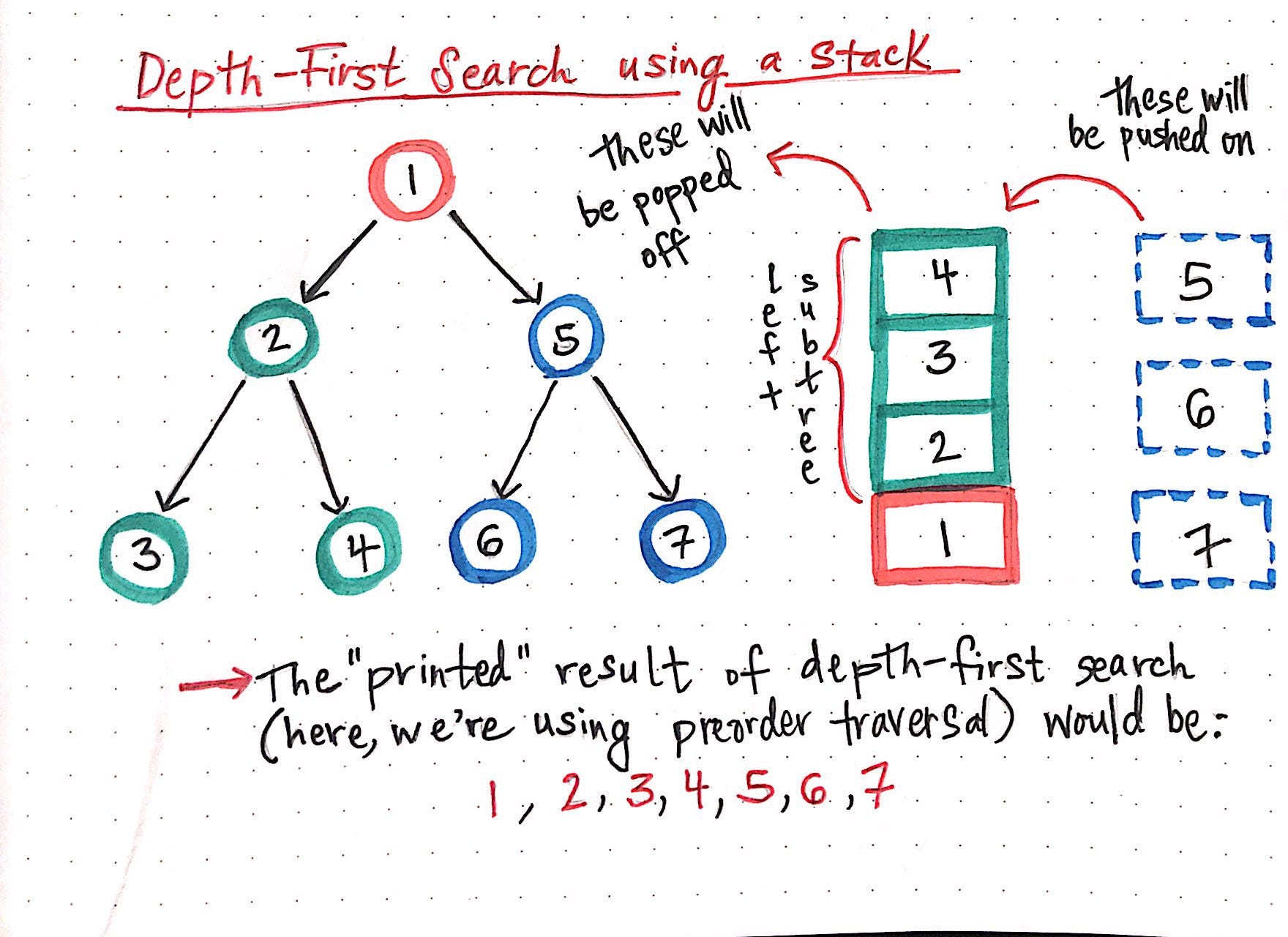
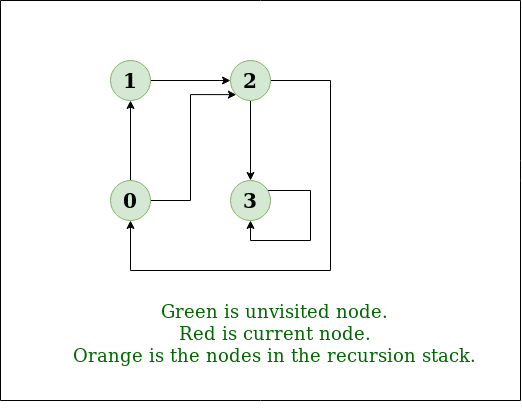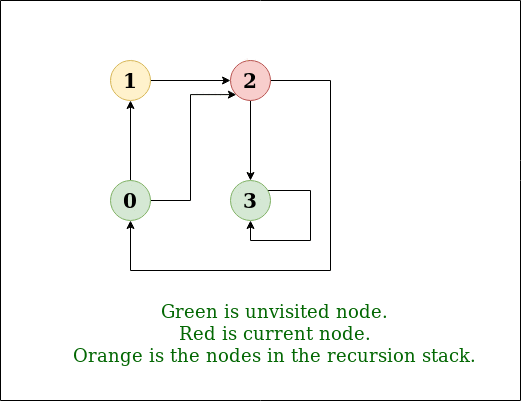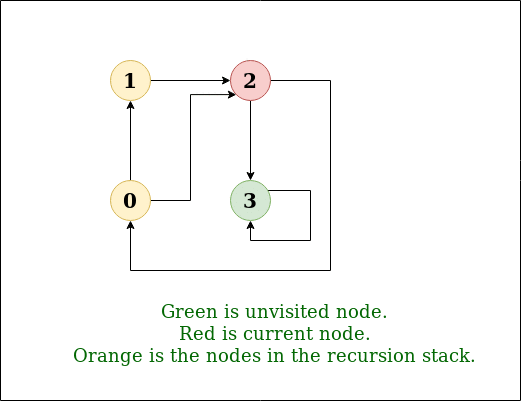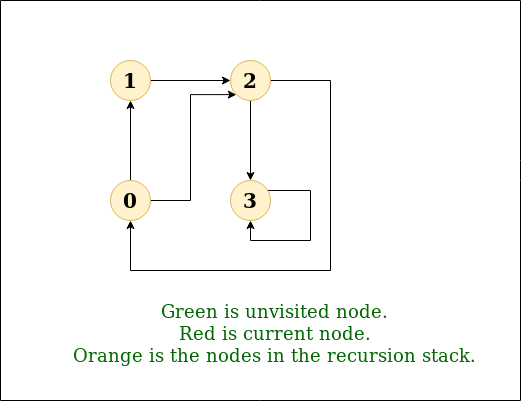
Dfs queue or stack. Depth first search dfs is an algorithm for traversing or searching tree or graph data structures. Dfs a can have multiple copies on the stack at the same time. The implementation of stack is quite simple. For every adjacent and unvsisted node of current node mark the node and insert it in the stack.
In this post we will see how to implement depth first search dfs in java. In previous post we have seen breadth first search bfs. A dynamic array will be enough to implement a stack. In this tutorial you will understand the working of dfs algorithm with code in c c java and python.
This is similar to bfs the only difference is queue is replaced by stack. Run a loop till the stack is not empty. We have also seen the implementation of both techniques. Summary to summarize you should be able to understand and compare the following concepts.
The algorithm starts at the root node selecting some arbitrary node as the root node in the case of a graph and explores as far as possible along each branch before backtracking. However the total number of iterations of the innermost loop of dfs a cannot exceed the number of edges of g and thus the size of s cannot exceed m. In dfs we might traverse through more edges to reach a destination vertex from a source. Implementation of iterative dfs.
Depth first search dfs is an important applications of stack. Depth first traversal or depth first search is a recursive algorithm for searching all the vertices of a graph or tree data structure. Insert the root in the stack. Bfs and dfs basically achieve the same outcome of visiting all nodes of a graph but they differ in the order of the output and the way in which it is done.
A version of depth first search was investigated in the 19th century by french mathematician charles pierre. Pop the element from the stack and print the element. Graph traversal algorithms breadth first search in java depth first search in java in dfs you start with an un. Moreover bfs consumes more memory than dfs.
Bfs can be used to find single source shortest path in an unweighted graph because in bfs we reach a vertex with minimum number of edges from a source vertex. The running time of dfs a is o n m. Previous next if you want to practice data structure and algorithm programs you can go through data structure and algorithm interview questions. Dfs depth first search uses stack data structure.
Another major difference between bfs and dfs is that bfs uses queue while dfs uses stack. We use stack when lifo principle is satisfied. While bfs stands for breadth first search dfs stands for depth first search.

Algorithm Obtaining A Powerset Of A Set In Java Stack Overflow Stack Overflow Algorithm Java

Bfs Versus Dfs Hands On Artificial Intelligence For Search
Check If The Two Given Stacks Are Same Geeksforgeeks
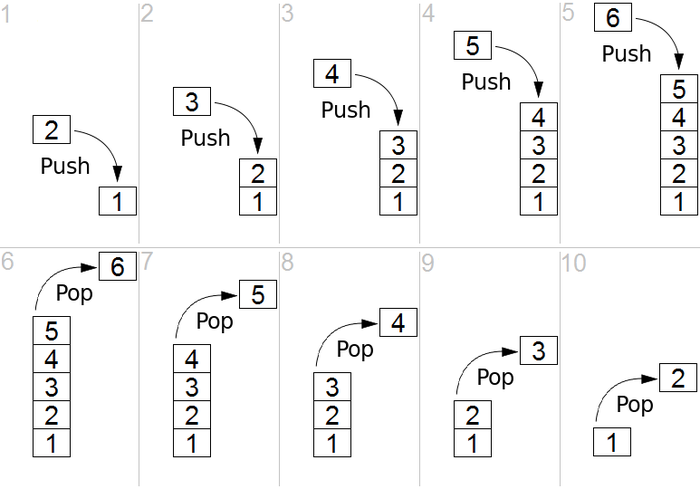
Data Structures In Python Series 2 Stacks Queues By Kojin Medium

Leetcode Word Ladder Word Ladders Words Ladder
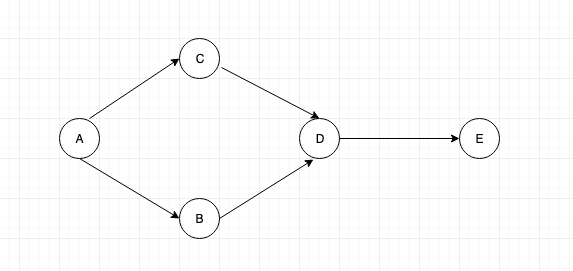
Graph Data Structure Tutorial 5 Graph Traversal Using Stack And Queue Prodevelopertutorial Com
The Coding Interview Interview Algorithm Coding
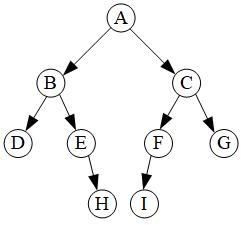
Java Implements Tree Depth First Search Dfs And Breadth First Search Bfs
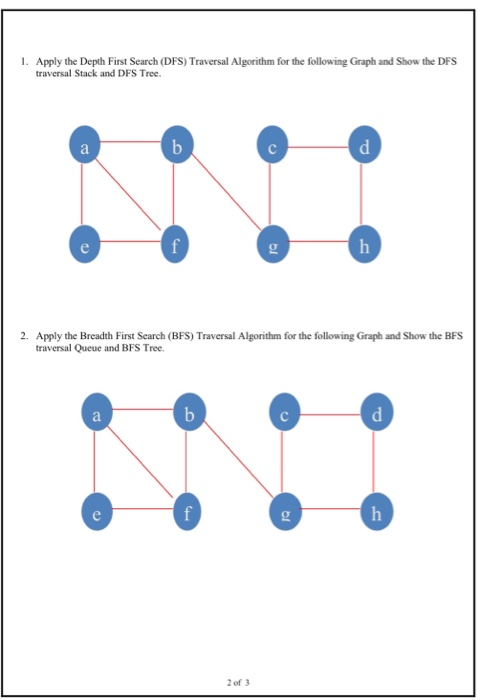
Solved 1 Apply The Depth First Search Dfs Traversal Al Chegg Com

Applications Of Stack The Crazy Programmer

Graph Depth First Traversal Dfs In Java Tutorialhorizon

Topic 14 C Bfs Youtube
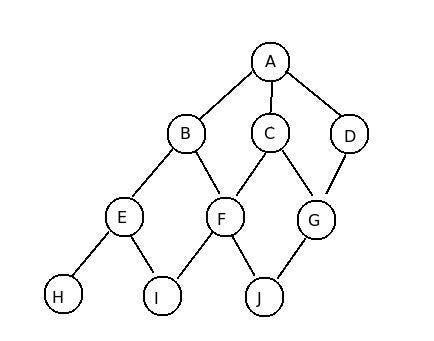
Dfs Vs Bfs In This Story I Will Compare Dfs And By Nihat Medium